
本文将详细分析不同格式的wav文件。
简介
wav即wave(下文统称为wav), 该文件格式是由微软开发的用于音频数字存储的标准,可应用于Windows、Linux和MacOS等多种操作系统,文件扩展名为.wav,是waveform的简写。
wav文件结构
在Windows下,大部分多媒体文件都遵循RIFF(Resource Interchange File Format,资源互换文件格式)格式来存储数据。
RIFF文件的基本存储单位称为块(chunk),一个遵循RIFF格式的文件由若干个chunk组成,每个chunk又由块标识、块长度和块数据三部分构成,其基本结构见表1:
| Field | Size(bytes) | Type |
|---|---|---|
| 块标识 | 4 | S8 * |
| 块长度 | 4 | U32 |
| 块数据 | S8 * |
**表1** `chunk`基本结构
- 块标识:用于标识块中的数据,由
4个ASCII字符组成,如不满4个字符则在右边以空格充填,如:RIFF、LIST、fmt和data等; - 块长度:用于标识块数据域中的数据长度,块标识域和块长度域不包括在其中,所以一个
chunk的实际长度为该值加8; - 块数据:存储块数据,若数据长度为奇数,则在最后添加一个
NULL;
特别需要注意的是,RIFF格式规定只有块标识为RIFF或LIST的块可以含有子块(subChunk),而其它块只可以包含数据。块标识为RIFF或LIST的块的结构与表1大致相同,只不过其块数据域分为两部分:
type:由4个ASCII字符组成,代表RIFF文件的类型,如WAVE和AVI,或者代表LIST块的类型,如avi文件中的列表hdrl和movi;data:实际的块内容,包含若干subChunk;
wav文件是非常简单的一种RIFF文件,其本身就是由一个块标识为RIFF的chunk和多个subChunk组成的一个chunk,其组成如下:
RIFF chunk:主块,必选,块标识为RIFF,说明这是一个RIFF文件,RIFF文件的第一个块标识必须是RIFF;Format chunk:子块,必选,块标识为fmt,用于存储文件的一些参数信息,比如采样率、通道数和编码格式等;Fact chunk:子块,可选,块标识为fact,基于压缩编码的wav文件必须含有fact块;List chunk:子块,可选,块标识为LIST,用于记录文件版权和创建时间信息;Data chunk:子块,必选,块标识为data,用于存储音频数据;
目前业界标准的wav文件仅由RIFF chunk、Format chunk和Data chunk组成: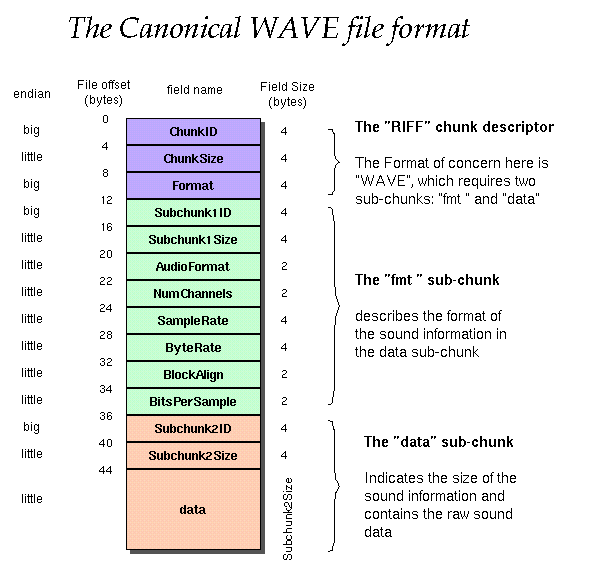
wav文件头格式
wav文件从数据类型上看,主要由文件头和数据体两部分组成:
- 文件头:由
RIFF chunk、Format chunk、List chunk和Fact chunk等组成,用于存储一些文件信息; - 数据体:由
Data chunk组成,用于存储音频数据;
标准格式
标准的wav文件头仅由RIFF chunk和Format chunk组成,长度为44个字节,格式见表2:
| file offset(bytes) | Field name | Field size(bytes) | type | endian | description |
|---|---|---|---|---|---|
| 0 | Chunk ID | 4 | S8 * | big | “RIFF”,表明为RIFF文件 |
| 4 | Chunk Size | 4 | U32 | little | 除了RIFF及自己之外,整个文件的长度,即文件总字节数减去8字节 |
| 8 | Format | 4 | S8 * | big | “WAVE”,表明为wav格式 |
| 12 | Subchunk1 ID | 4 | S8 * | big | “fmt “ |
| 16 | Subchunk1 Size | 4 | U32 | little | 表示fmt数据块即subchunk1除了Subchunk1 ID和Subchunk1 Size之后剩下的长度,一般为16, 大于16表示存在扩展区域,可选值为16、18、20、40等 |
| 20 | AudioFormat | 2 | U16 | little | 编码格式,即压缩格式,0x01表示pcm格式,无压缩,参见表3 |
| 22 | NumChannels | 2 | U16 | little | 音频通道数,单声道为1,立体声或双声道为2 |
| 24 | SampleRate | 4 | U32 | little | 采样频率,每个通道单位时间采样次数,可选值为16000kHz和44100kHz等 |
| 28 | ByteRate | 4 | U32 | little | 数据传输速率,可用此估算缓冲区长度,ByteRate = SampleRate * NumChannels * (BitsPerSample / 8) |
| 32 | BlockAlign | 2 | U16 | little | 采样一次的字节数,即一帧的字节数,表示块对齐的内容(数据块的调整数),播放软件一次处理多少个该长度的字节数据,以便将其用于缓冲区的调整,BlockAlign = NumChannels * (BitsPerSample / 8) |
| 34 | BitsPerSample | 2 | U16 | little | 采样位宽,即每个采样点的bit数,可选值8、16或32等 |
| 36 | Subchunk2 ID | 4 | S8 * | big | “data” |
| 40 | Subchunk2 Size | 4 | U32 | little | 音频数据的总长度,即文件总字节数减去wav文件头的长度 |
| 44 | Data | little | 音频数据 |
**表2** 标准的`wav`文件头格式
通过wav文件头信息,我们可以计算出音频时长:
1 | 音频时长(s) = Subchunk2 Size / ByteRate |
压缩编码格式
wav文件几乎支持所有ACM规范的编码格式,其信息存储在wav文件头偏移20、21两个字节中,常见的压缩编码格式见表3:
| 格式代码 | 格式名称 | Format chunk 长度 | 是否有Fact chunk |
|---|---|---|---|
| 0 (0x0000) | unknown | unknown | unknown |
| 1 (0x0001) | PCM/uncompressed | 16 | 无 |
| 2 (0x0002) | Microsoft ADPCM | 18 | 有 |
| 3(0x0003) | IEEE float | 18 | 有 |
| 6 (0x0006) | ITU G.711 a-law | 18 | 有 |
| 7 (0x0007) | ITU G.711 µ-law | 18 | 有 |
| 17 (0x0011) | IMA ADPCM | unknown | unknown |
| 20 (0x0016) | ITU G.723 ADPCM (Yamaha) | unknown | unknown |
| 49 (0x0031) | GSM 6.10 | 20 | 有 |
| 64 (0x0040) | ITU G.721 ADPCM | unknown | 有 |
| 80 (0x0050) | MPEG | unknown | unknown |
| 65,534 (0xFFFE) | 扩展格式标识 | 40 | unknown |
| 65,536 (0xFFFF) | Experimental | unknown | unknown |
**表3** 常见的压缩编码格式
扩展格式
当然,也不是所有的wav文件头都是44个字节的,比如通过FFmpge编码而来的wav文件头通常大于44个字节,目前比较常见的wav文件头长度有44字节、46字节、58字节和98字节。
Format chunk扩展
当wav文件采用非PCM编码即压缩格式时,会扩展Format chunk,在其之后扩充了一个数据结构,见表4:
| file offset(bytes) | Field name | Field size(bytes) | type | description |
|---|---|---|---|---|
| 24 | extand size | 2 | U16 | 除其自身外的扩展区域长度 |
| 26 | extand area | 包含扩展的格式信息,其长度取决于压缩编码类型。当某种编码格式(如ITU G.711 a-law)使扩展区的长度为0时,该字段还必须保留,只是长度字段的数值为0。 |
**表4** 标准Format chunk扩展格式
由此可以得出,如果
Subchunk1 Size等于0x10(16),表示不包含Format chunk扩展,wav文件头长度为44字节;如果大于0x10(16),则包含Format chunk扩展,扩展长度的最小值为18(16+2),此时wav文件头大于44字节。
当编码格式代码为0xFFFE时,Format chunk扩展长度为24字节,格式见表5。
| file offset(bytes) | Field name | Field size(bytes) | type | description |
|---|---|---|---|---|
| 24 | 扩展区长度 | 2 | U16 | 值为22 |
| 26 | 有效采样位数 | 2 | U16 | 最大值为 每个采样字节数 * 8 |
| 28 | 扬声器位置 | 4 | U32 | 声道号与扬声器位置映射的二进制掩码 |
| 32 | 编码格式 | 2 | U16 | 真正的编码格式代码 |
| 34 | 14 | 值为{\x00, \x00, \x00, \x00, \x10, \x00, \x80, \x00, \x00, \xAA, \x00, \x38, \x9B, \x71} |
**表5** 编码为0xFFFE的Format chunk扩展格式
Fact chunk
采用压缩编码(修订版Rev.3以后出现的编码格式)的wav文件必定有含有Fact chunk,其结构符合标准chunk结构,参见表1。
Fact chunk的块标识符为”fact“,块长度至少为4个字节,目前其只有一个块数据内容,即每个声道采样总数,或采样帧总数。该值等于Subchunk2 Size / BlockAlign。
值得注意的是,在实测中发现,将压缩编码格式文件转换成PCM编码格式后,原Fact chunk仍然存在。
wav文件动态解析库
wav文件格式是一种极其简单的文件格式,如果对其结构足够熟悉,完全可以通过代码正确读写,从而免去引入一些复杂的中间库,降低复杂度,提高工作效率。
这里提供了一个wav文件动态解析库,欢迎使用。
